
Este es un Proyecto desarrollado por el Grupo Tecling.com por encargo de la Revista Perspectiva Educacional (RPE). Consiste en un análisis terminológico y de contenidos de un corpus de revistas de Educación en inglés y castellano. El objetivo de este proyecto es identificar los temas centrales así como los autores y publicaciones de referencia de la investigación internacional actual en el campo de la Educación. Para tal fin, se propone la aplicación de técnicas de procesamiento de lenguaje natural para analizar un corpus de revistas especializadas del área, que resulta en la extracción de un glosario de términos, una base de autores y otra de referencias bibliográficas. A partir de estos productos se ha desarrollado a su vez un sistema que identifica los términos y temas presentes y ausentes de las distintas revistas, las publicaciones y autores más citados y, finalmente, un sistema de recomendación automática de revisores para los artículos que son enviados a RPE.
El proyecto tiene distintas etapas, que se agrupan en tres productos principales:
1.1. Constitución del corpus
Para la creación de la base de datos terminológica del área primero se procedió a la constitución de un corpus de revistas del área que fueron elegidas por la Dirección de RPE. Para esto se procedió a la descarga y conversión automática de los artículos publicados en los últimos 15 años de cada una de las revistas que conforman la muestra, constituida por la misma RPE y las publicaciones expuestas en la tabla 1.
| Revista | URL | Código | tokens |
|---|---|---|---|
| Perfiles Educativos | https://perfileseducativos.unam.mx/iisue_pe/index.php/perfiles | perfilesEducativos | 8.616.554 |
| Magis | https://revistas.javeriana.edu.co/index.php/MAGIS | magis | 4.596.030 |
| Revista Complutense en Educación | https://revistas.ucm.es/index.php/RCED | complutense | 11.865.389 |
| Revista Electrónica de Investigación Educativa | https://redie.uabc.mx/redie | redie | 6.653.676 |
| Teaching and teacher education | https://www.sciencedirect.com/journal/teaching-and-teacher-education/vol/122/suppl/C | teaching | 8.852.278 |
| Revista Mexicana de Investigación Educativa | https://comie.org.mx/revista/v2018/rmie/index.php/nrmie/issue/archive | mexicana | 11.319.351 |
| Educacao y pesquiesa | https://www.scielo.br/j/ep/ | edupesquisa | 6.246.585 |
| Educacion y sociedad | https://revistaeduysoc.acees.net/index.php/revistaeduysoc | eduysoc | 219.634 |
| Pensamiento educativo | https://pensamientoeducativo.uc.cl/index.php/pel | pensamiento | 7.947.512 |
| Profile: Issues in Teachers' Professional Development | https://revistas.unal.edu.co/index.php/profile | profileIssues | 4.833.302 |
| REICE | https://revistas.uam.es/reice/issue/archive | reice | 7.649.130 |
| Perspectiva Educacional | http://www.perspectivaeducacional.cl/index.php/peducacional | perspectiva | 2.162.259 |
1.2. Procesamiento del corpus y extracción de terminología
En esta etapa se llevaron a cabo las siguientes tareas:
Para llevar a cabo estas operaciones de manera automática se desarrolló una herramienta específica, que constituye una nueva versión del software de extracción de terminología Termout. Este sistema se encuentra en la siguiente URL:
http://www.termout.org
A modo ilustrativo, la figura 1 muestra una captura de pantalla con un fragmento de resultado de la extracción terminológica. La Figura 2 muestra un fragmento de la alineación bilingüe de los términos. Como es natural, al tratarse de operaciones automatizadas, en algunos casos se producen errores, y por eso el sistema también permite la edición manual de la base de datos, así como su exportación o importación del glosario en formatos estándar.
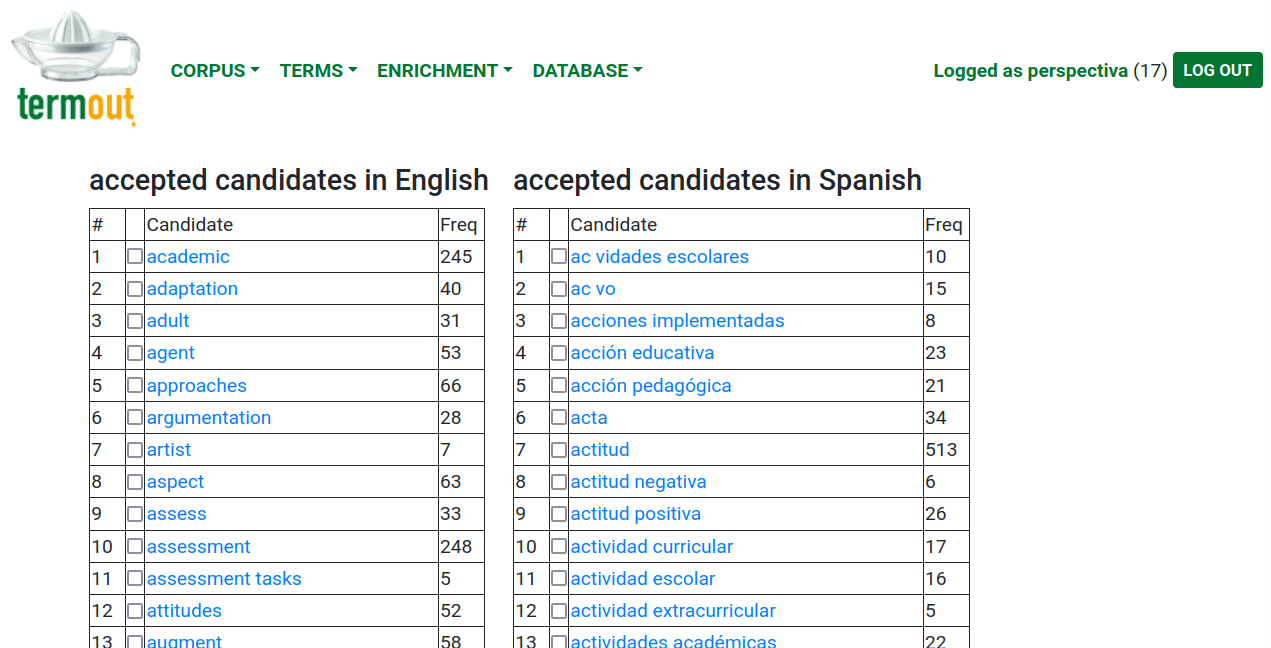
Figura 1: Captura de pantalla de un fragmento de resultados de la extracción terminológica
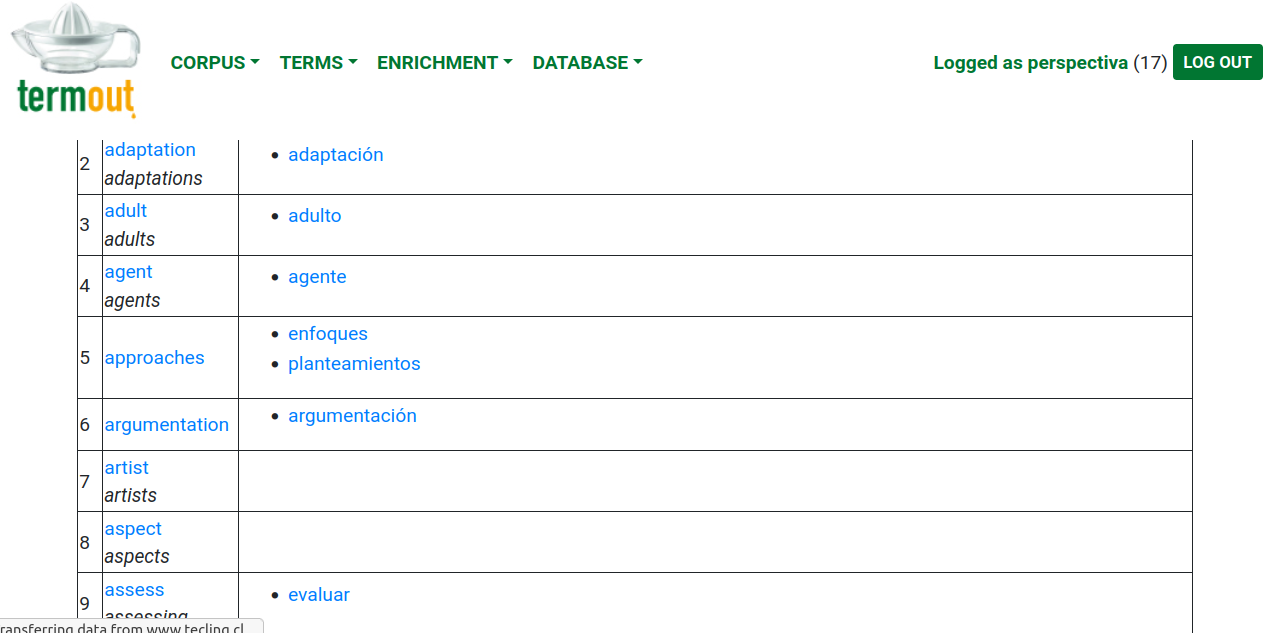
Figura 2: Captura de pantalla de un fragmento de alineación bilingüe de los términos
El resultado de esta etapa es un glosario general del área de Educación, en inglés y castellano, que podrá ir completándose paulatinamente con informaciones que se extraigan automáticamente del corpus con Termout
Actualmente, la base de datos contiene 7.355 candidatos a término en castellano y 8.925 en inglés, totalizando 16.280. Esta cantidad de términos representa un buen material para la producción de diccionario especializado de amplia cobertura.
1.3. Cruce entre términos y revistas
Una vez concluido el proceso de extracción de los términos de cada una de las revistas analizadas, los resultados se configuraron en una nueva base de datos que permite hacer el cruce y seguimiento de los términos por cada revista.
Esta función permite obtener, de manera rápida, listados de términos que están ya sea muy presentes o muy ausentes en cualquiera de las revistas del corpus. Esto se calcula por medio de un coeficiente que compara la frecuencia de un término en una revista en particular con su frecuencia en el total del corpus. Los usuarios pueden seleccionar cualquier revista y el criterio de ordenamiento, para mostrar priemro los términos más presentes o los más ausentes. La Figura 3 muestra un fragmento de este ordenamiento para el caso de RPE.
1.4. Clustering semántico de términos
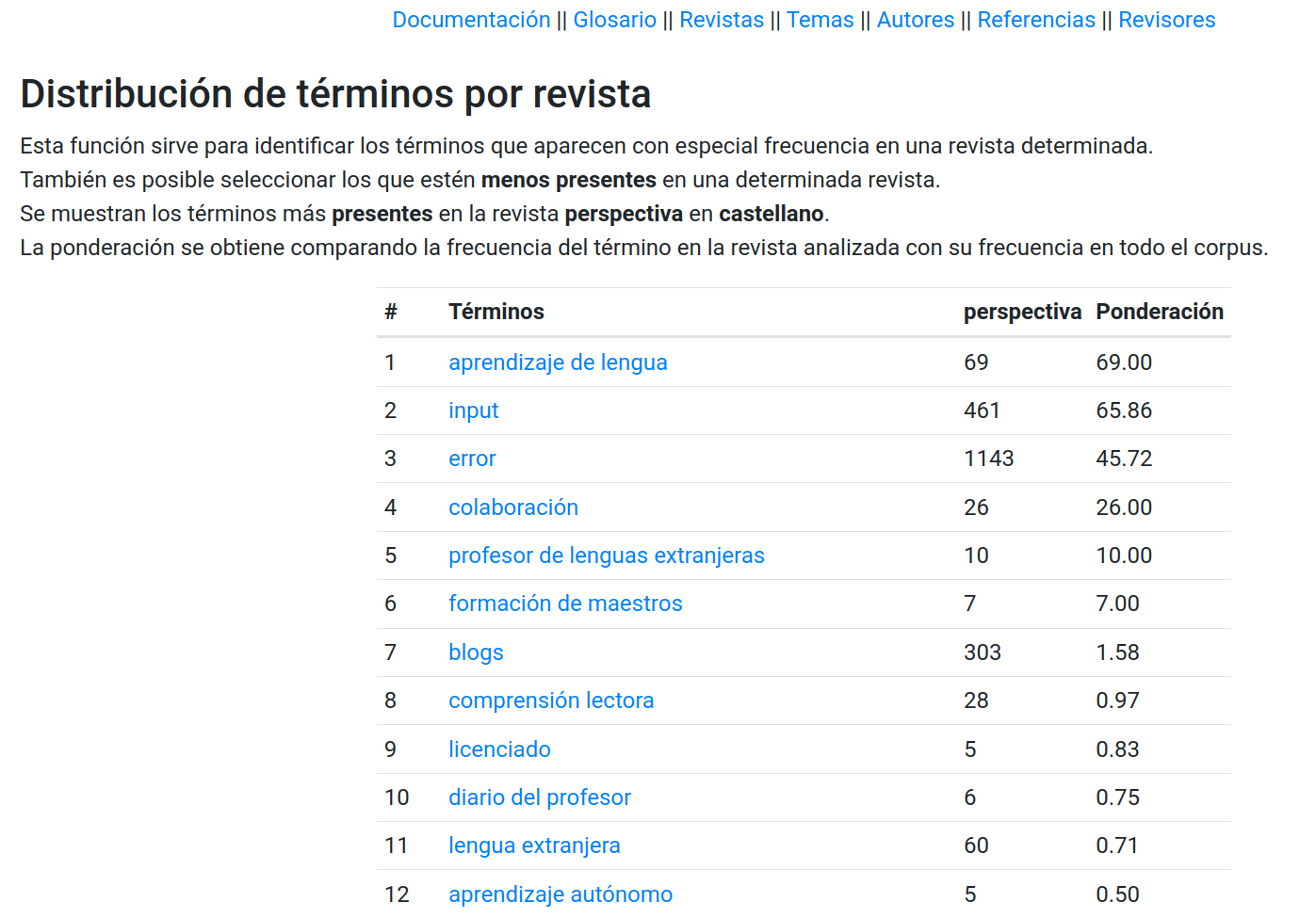
Figura 3: Captura de pantalla de la interfaz que ofrece el cruce entre términos y revistas
De manera complementaria al trabajo con la terminología, se decidió agrupar estas unidades terminológicas por temas con el objeto de organizar mejor los términos y facilitar de ese modo el análisis de los resultados del proyecto.
Para ello se aplicó una técnica estadística de clustering basado en grafos. Esta es una técnica de asociación estadística que mide la coaparición de los términos en los mismos fragmentos de texto. Aplicando esta técnica, fue posible agrupar el total de los términos en 346 clusters o grupos de términos que están semánticamente relacionados o refieren a un mismo tema global. La figura 4 muestra una captura de pantalla de estos resultados.
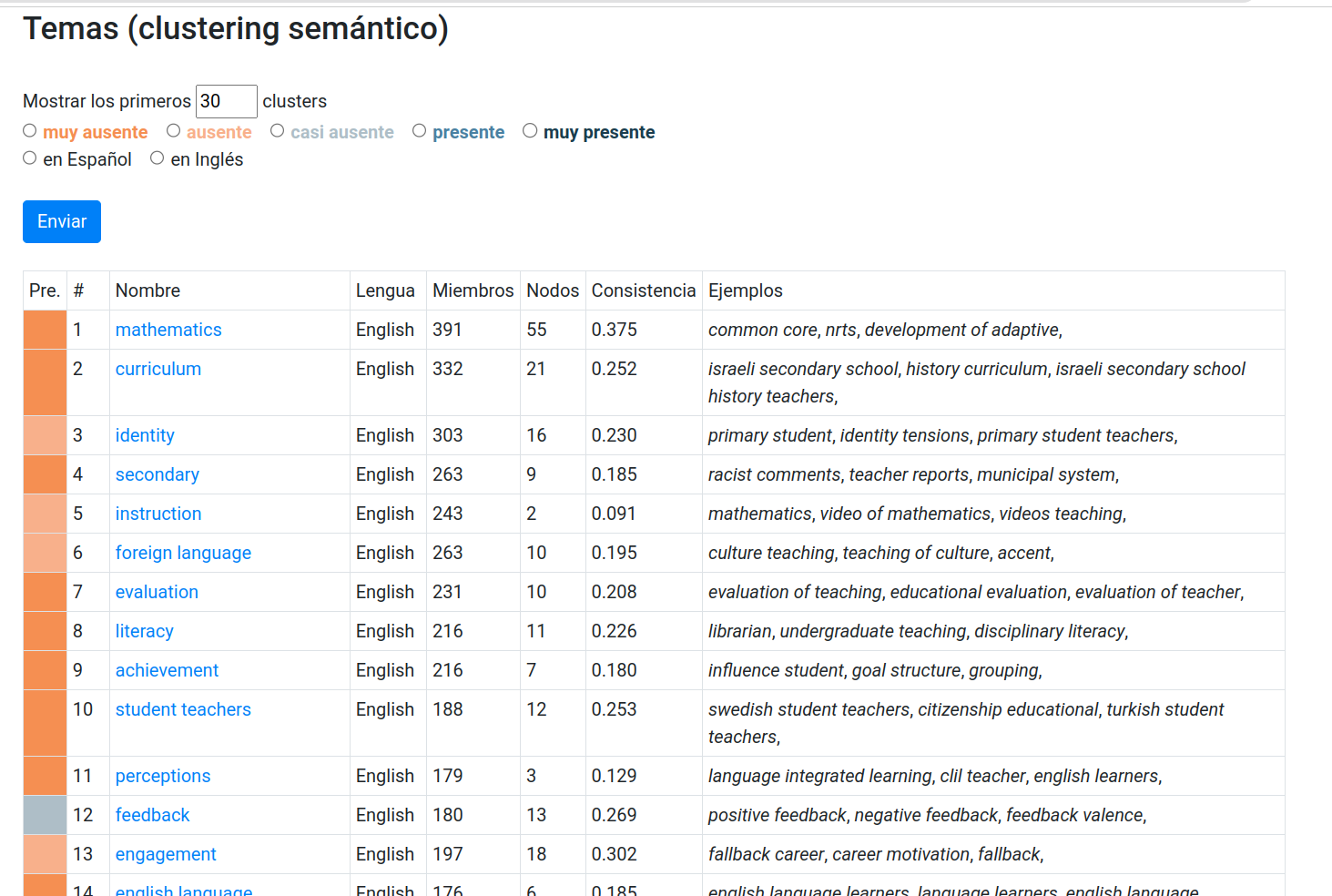
Figura 4: Captura de pantalla de la interfaz que muestra el resultado del clustering semántico
En esta función, el sistema ofrece primero una tabla con todos los clusters ordenados por lengua (primero en inglés, luego en castellano) y, dentro de cada lengua, por importancia, que viene dada por el tamaño medido en cantidad de términos que forman parte del cluster. Los resultados también se presentan señalados con un código de colores, que representan el grado en que cada tema se encuentra presente o ausente en RPE. De esta forma, los clusters se señalan con una escala que va del color naranja más intenso, que representa mayor ausencia en RPE (más intenso si el tema se trata en más revistas y a la vez está ausente en RPE), hasta el azul más oscuro, para señalar que el tema se encuentra suficientemente cubierto por RPE. Del total de 346 clusters, 72 (21%) están presentes o muy presentes en RPE, mientras que 272 (79%) están ausentes o medianamente ausentes.
Además del código de color, el sistema también ofrece una propuesta de nombre para el cluster, en la tercera columna de la tabla de resultados (Name). Este nombre es simplemente un término de la base de datos que es elegido por el sistema como representativo de cada cluster. Entre otras estadísticas de tamaño y consistencia interna de cada cluster, el sistema ofrece también en la última columna de la tabla un reducido número de ejemplos de los términos que se encuentran en cada cluster y que ayudarán a formarse una mejor idea de lo que cada cluster representa antes de iniciar la navegación por cada uno de ellos.
Solo mediante el examen de esta tabla de resultados es posible advertir que hay temáticas que se encuentran ampliamente tratadas en otras revistas. Naturalmente, hay menor cobertura de RPE (mayor presencia del naranja) en los clusters en inglés. De cualquier modo, el dato es útil porque esto es indicativo de ausencia de estos términos en los artículos de la Revista, ya que justamente están en inglés los términos que representan conceptos centrales en cada artículo, los que van en la versión inglesa del título, el resumen, las palabras clave y los títulos de referencias bibliográficas citadas.
Luego cada cluster tiene una página específica, en la que se muestra un grafo de coocurrencia y tablas con la distribución de los términos así como del cluster en general por cada revista de la muestra. De esta forma es posible apreciar algunos clusters que tienen comparativamente menor presencia en RPE, como el correspondiente a burnout (Figura 5) o desarrollo moral (Figura 6). Además, por cada cluster aparece la distribución de los términos por revista y el listado de los autores más relacionados con cada cluster (Figura 7).
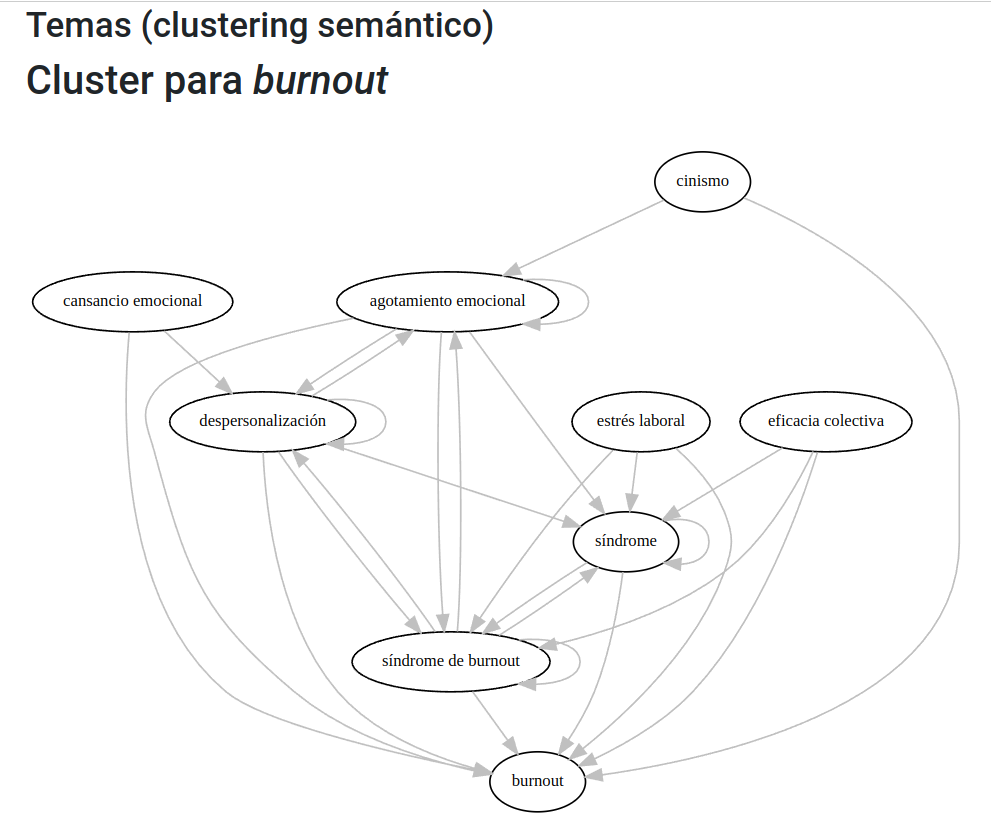
Figura 5: Cluster para burnout
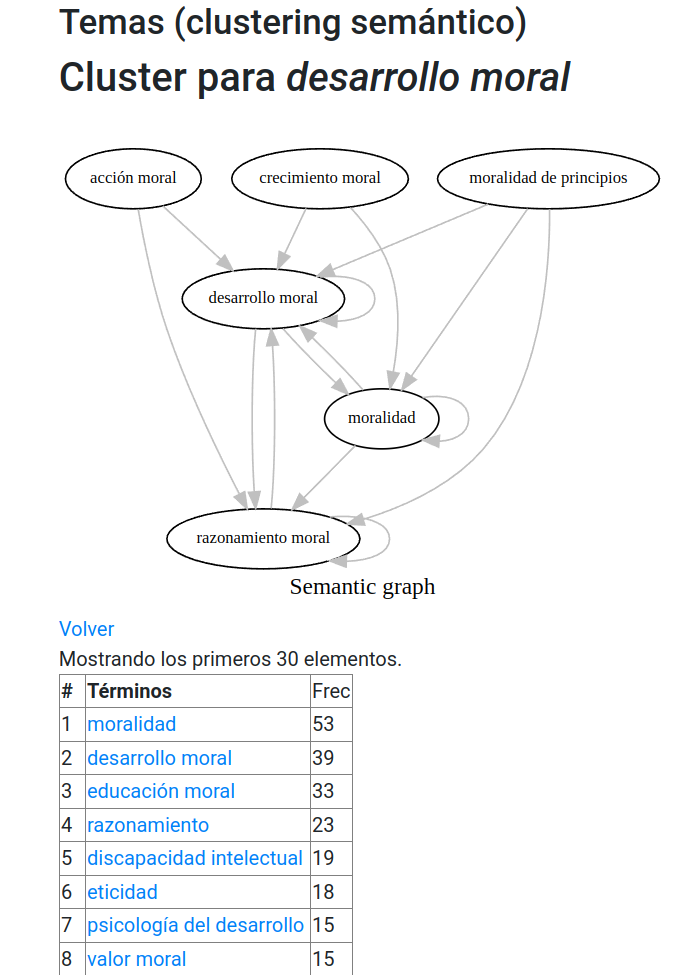
Figura 6: Cluster para desarrollo moral
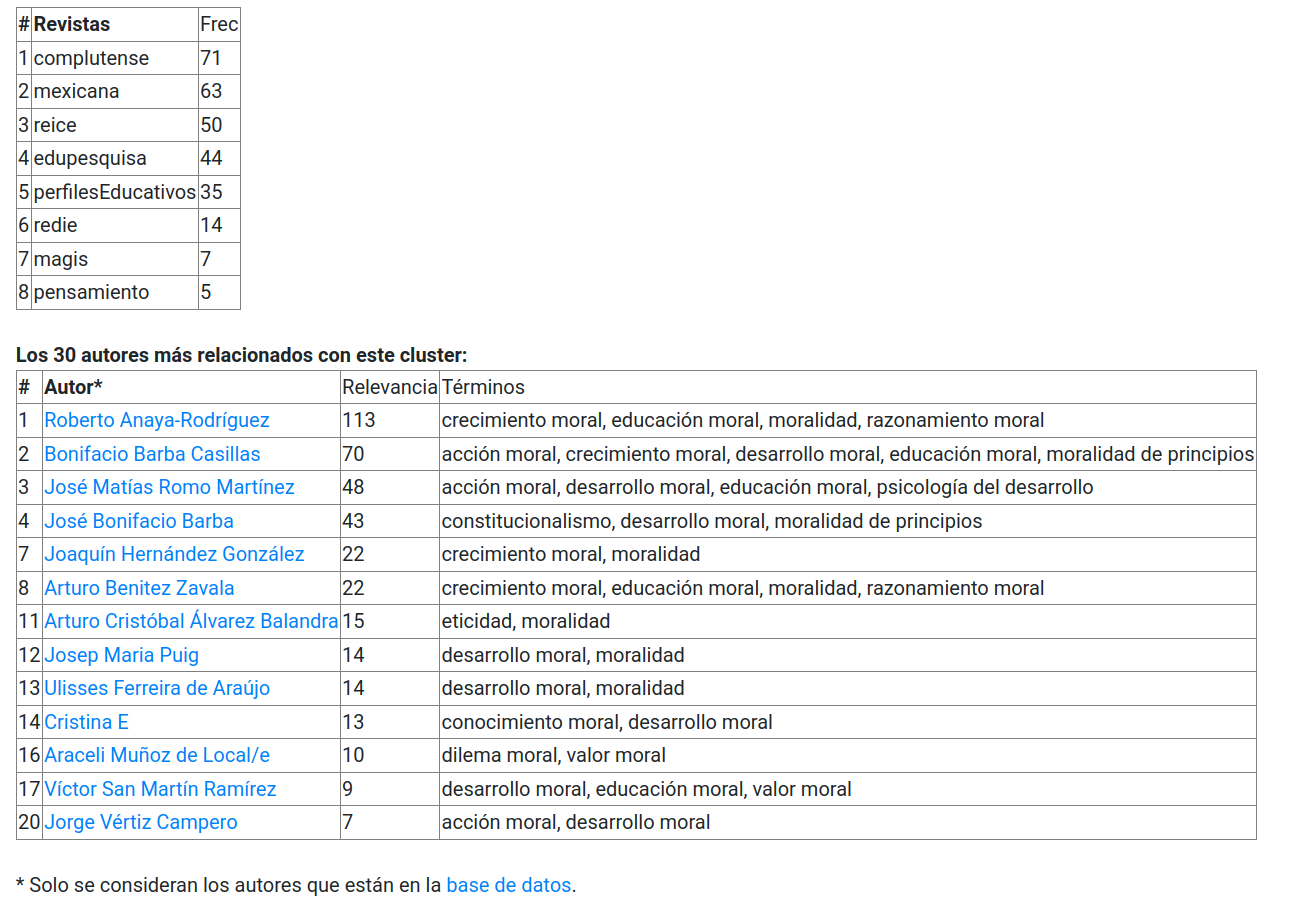
Figura 7: Distribución del cluster por revista y listado de autores más relacionados
Producto 2
Al igual que en el caso del Producto 1 con la terminología, en este producto se determina por un lado qué autores y publicaciones son los que tienen mayor centralidad en el campo y por otro se detectan autores o referencias bibliográficas que tengan menor presencia en RPE. Esto se lleva a cabo por medio de la contabilización de autores y referencias que presentan mayor frecuencia y dispersión. De la misma manera que en el caso del Producto 1, se ofree aquí una interfaz para la consulta de ambas bases de datos.
Base de datos de autores
El segundo producto es la constitución, por un lado, de
una base de datos de autores
de los artículos del corpus. En esta base de datos, cada entrada es el nombre y apellido de un/a autor/a, y cada registro contiene además la o las direcciones de correo electrónico, el género del autor (masculino/femenino), la afiliación, las revistas en las que publica, la lengua en que escribe, los temas de investigación que cultiva, enlaces a los artículos que ha publicado y las referencias que ha citado en esos artículos. La base de datos contiene en este momento más de 10.000 autores.
Base de datos de referencias bibliográficas
En cuanto a la base de datos de referencias bibliográficas, esta consiste en un listado de más de 100.000 registros (sin repeticiones). Cada referencia es clasificada automáticamente según el tipo (artículo, libro, capítulo de libro, etc.), separada en los distintos campos (autor, año, título, editorial o revista, etc.) y enlazada con los artículos en los que es citada. Se controla, además, si los autores citados están en la base de datos de autores. La interfaz de búsqueda permite hacer consultas por campo y además hacerlo mediante palabras, fragmento de palabra o expresiones regulares. Devuelve la tabla con los registros coincidentes y además una estadística con la frecuencia con que cada referencia citada en cada una de las revistas del corpus (Figura 9).
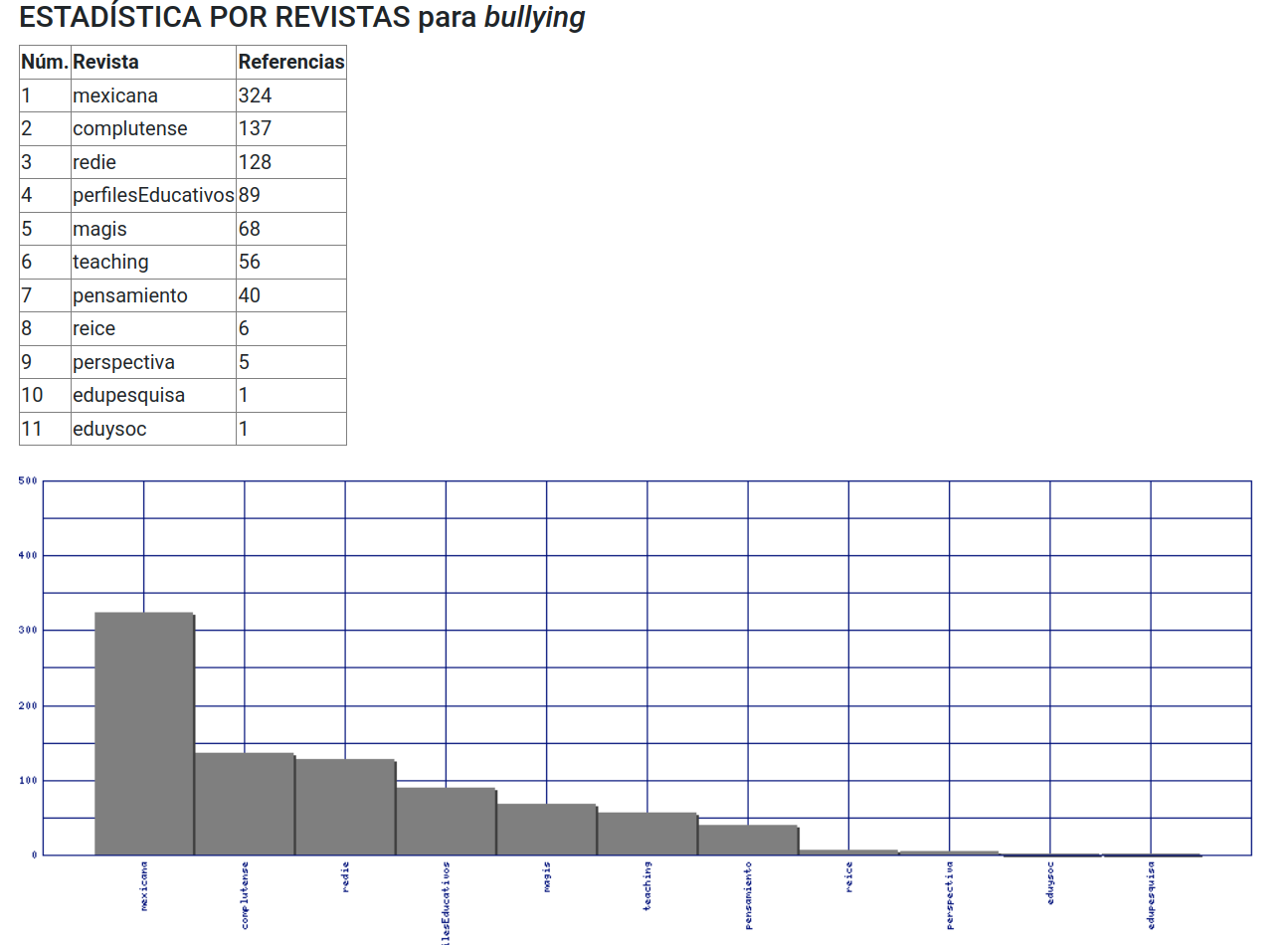
Figura 9: Distribución por revistas del término bullying
Producto 3
Sistema de recomendación de revisores
Se implementó un sistema de recomendación automática de revisores que explota los dos productos anteriores. A partir de un determinado texto que se presenta como entrada, este sistema es capaz de ofrecer una lista ordenada de nombres de especialistas candidatos a revisores. Esto se lleva a cabo por medio de un cálculo de similitud entre los contenidos del texto ingresado y las líneas de investigación cultivadas por cada autor, según lo indicado en la base de datos de autores. Para esta detección de similitud entre el texto de entrada y los candidatos a revisores se tiene en cuenta tanto la coincidencia en terminología (a partir de la base de datos de términos) como las referencias que citan (a partir de la base de datos de referencias).
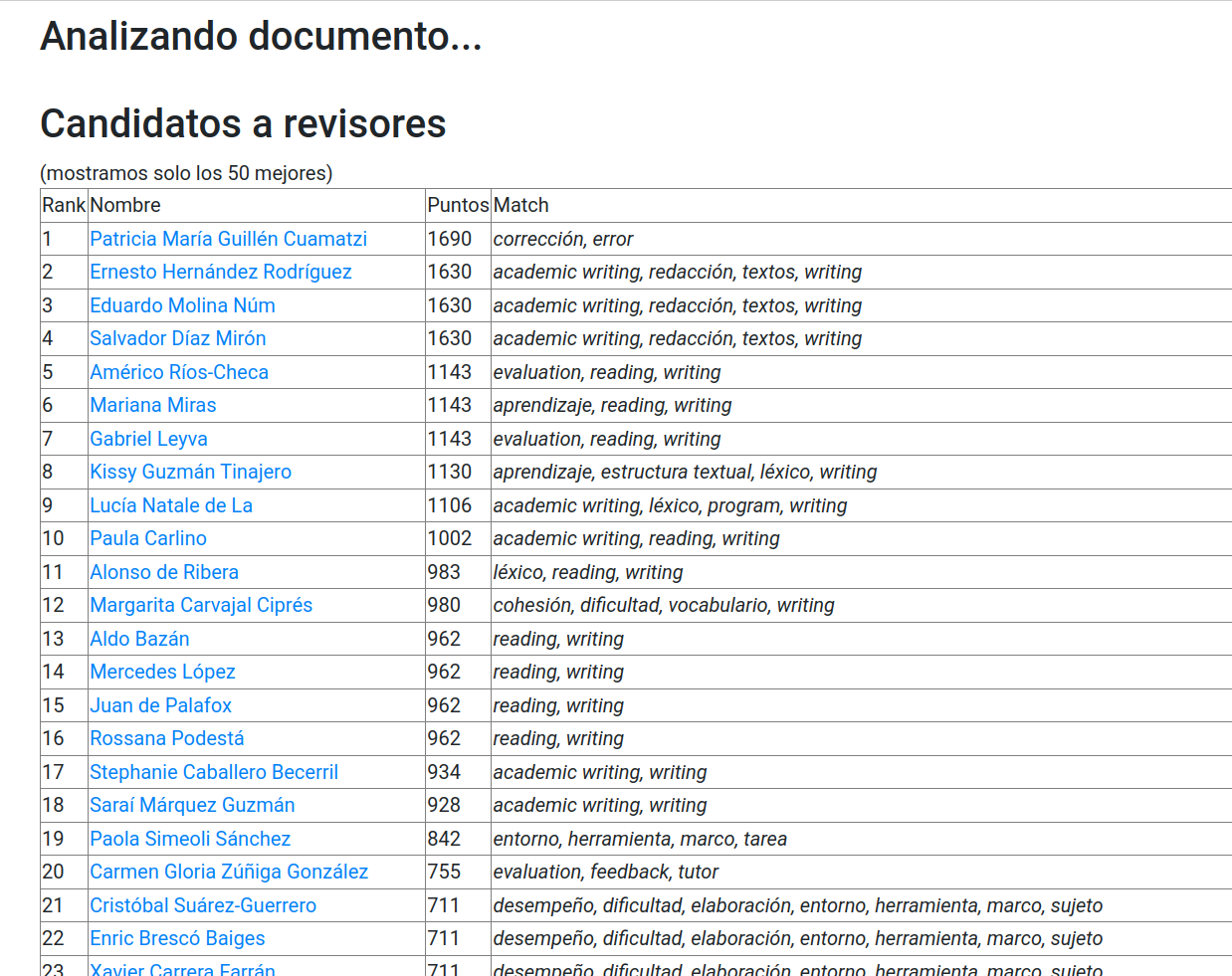
Figura 10: Selección de candidatos a revisor para un artículo